Prompt Engineering(提示词工程)应用实践-Prompt自优化框架
典型的Prompt自优化框架
| 框架名称 | 论文名称 | GitHub地址 |
|---|---|---|
| DSPy(Declarative Self-improved Language Programs in Python) | DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines | DSPy官网;DSPy GitHub |
| TextGrad | TextGrad: Automatic “Differentiation” via Text | TextGrad GitHub |
| PromptWizard | PROMPTWIZARD:TASK-AWARE PROMPT OPTIMIZATION FRAMEWORK | PromptWizar GitHub;微软地址 |
| GRAD-SUM | GRAD-SUM: Leveraging Gradient Summarization for Optimal Prompt Engineering | |
| Ell | 前OpenAI科学家William Guss开源项目, ELL是轻量级提示工程库,将提示视为函数,通过词法闭包实现提示版本控制、优化、跟踪、可读性和可视化 | Ell GitHub |
| StraGo(Strategic-Guided Optimization) | StraGo: Harnessing Strategic Guidance for Prompt Optimization | |
| ERM(Exemplar-Guided Reflection with Memory mechanism) | Efficient and Accurate Prompt Optimization: the Benefit of Memory in Exemplar-Guided Reflection |
一个界定良好的问题,就已经将问题解决了一半。——美国思想家杜威
如果给我1小时解答一道决定我生死的问题,我会花55分钟弄清楚这道题到底咋问什么。一旦清楚它到底在问什么,剩下的5分钟足够回答这个问题。——爱因斯坦,只有好的问题,才会有好的答案。
Prompt模板基本框架示例
Prompt = Role + Instruction + [Context/Background Information] + [Examples/Templates] + [Specific Requirements/Details] + Text Input/User Question
Role(角色):Role位于首行,按应用需要固定一个角色;
Instruction(指令):简短,清晰,高度概括任务要求,前后风格保存一致
Context/Background Information(上下文/背景信息):独立成段,格式清晰;明确段落名称;保持清晰结构和段落逻辑
可采用静态/动态Context方法,在系统运行时获取上下文信息或者在系统中利用穷举预置好上下文信息。
Examples/Templates(示例/模板):示例均衡全覆盖,要具备指导实施能力;独立成段,格式清晰;明确段落名称;保持清晰结构和段落逻辑
可以使用单样本提示(one-shot prompting)、少样本提示(few-shot prompting)方法,通过少量样本引导LLM对特定任务进行学习和执行,以产出相似风格或主题的内容。
Specific Requirements/Details(具体要求/细节):明确输出格式要求;明确任务细节要求,并完成对指令细化补充
Text Input/User Question(输入文本/用户问题):数据真实有效多样化;和Prompt其他元素隔离开
Prompt模板典型技巧
将模糊要求细化成具体要求
描述输出格式
使用分割符号和强调符号
描述操作步骤
提供相关材料和背景
使用示例(FewShot),解决相似的问题
使用思维链引导,让模型慢慢思考(CoT)
DSPy-Prompt自优化框架
简介
开发团队:斯坦福大学NLP团队(The Stanfold NLP Group)
开源日期:2023-01-09(https://api.github.com/repos/stanfordnlp/dspy)
开源协议:MIT license
论文名称:DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
DSPy官网:https://dspy.ai/
DSPy中文文档:https://www.aidoczh.com/docs/dspy/docs/intro
GitHub地址:https://github.com/stanfordnlp/dspy
GitHub数据(截止2025/09/20):Fork 2.3k, Star 28.5k, Contributors 347, 最近版本3.0.3
设计目标:借鉴神经网络,实现对LLM的Prompt和权重进行自优化的框架
解决痛点:解决Prompt手动持续调整问题,实现自动调优;解决切换LLM模型Prompt适配问题,实现自动优化;Prompt开发流程工程化,规范迭代开发;
总体设计
思路:通过编程方式,将模块和每个步骤的参数(Prompt组件和LLM权重)分离,对组成提示词的部分进行模块化;引入LLM驱动的算法优化器,在给定希望最大化度量指标情况下,调整LLM的提升和权重。
DSPy应用程序构建过程及流图:
- 收集数据集(Dataset):提前准备输入输出示例(问答对),用于后续Prompt优化。
- 编写DSPy程序:利用DSPy的签名(Signature)和模块(Module)功能,定义程序逻辑和组件之间的信息流动步骤,用于完成Prompt优化任务。
- 定义验证程序:利用指标(Metrics)和优化器,优化程序性能和确定优化后效果的验证方向。
- 编译并运行DSPy程序:调用优化器内的编译器方法(compile),将程序代码、优化器、验证指标、数据集调动起来,程序自动优化Prompt,包括调整提提示或微调。
- 迭代改进:不断通过优化数据、程序和验证逻辑重复上述过程,知道获得满意的Prompt为止。
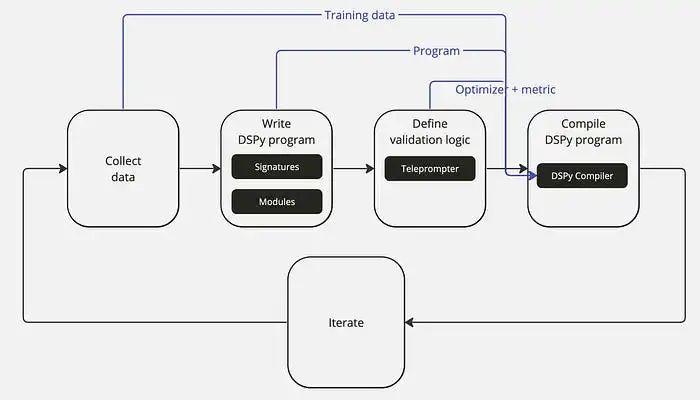 于PyTorch灵活组合通用模块构建神经网络一样,DSPy可以在任何LLM的应用中自由组合模块。编译DSPy应用程序的过程类似于PyTorch训练神经网络的过程。
于PyTorch灵活组合通用模块构建神经网络一样,DSPy可以在任何LLM的应用中自由组合模块。编译DSPy应用程序的过程类似于PyTorch训练神经网络的过程。
核心模块
签名(Signature):声明性规范,由输入内容的详细描述、输出内容的详细描述、任务描述组成。将输入内容、输入内容设置在变量中,在推理过程中转换为提示词内容。实现定义模块的输入输出行为,指导LLM执行什么任务的功能, 专注定义任务的预期结果。
使用方法:标准定义、内联定义两种。
内联定义(简单方法):使用简单字符串表示,用“->”符号关联输入和输出
1 | import dspy |
标准定义:涉及输入输出数据多而且需要添加备注时,用来定义复杂的输入输出关系。
1 | import dspy |
模块(Module):Prompt组装。将提示词中的关键部分设置到变量中,在使用LLM前,将提示词各要素组装完整。
关键特性:
- 每个内置模块负责特定的Prompt Engineering技术并处理DSPy签名。
- DSPy模块有可学习参数,涉及Prompt组件和LLM权重,实现处理输入并根据优化后的参数生成输出。
- DSPy模块可组合成更大更复杂的模块。
相关组件:
| 组件 | 用途 |
|---|---|
| dspy.Predict | 处理输入输出字段,生成指令,构建指定类型的提示词模板 |
| dspy.ChainOfThought(CoT) | 继承自Predict,提供CoT模式相关提示词组装和大模型调用功能,通过推理步骤逐步逼近答案,可以使用Hint来提示LLM如何推理。 |
| dspy.ChainofThoughtWithHint | 使用Parallel模块并行处理dspy.Example实例列表, 增强了ChainOfThought,增加推理提示的选项 |
| dspy.MultiChainComparison | 增加多重链比较功能 |
| dspy.ProgramOfThought(PoT) | 根据输入字段生成并可执行Python代码,通过迭代细化产生单个输出字段 |
| dspy.Retrieve | 从检索模块检索信息, 根据query返回k个查询结果 |
| dspy.ReAct | 提供React思维模式(思考、行动、观察)执行步骤,调整响应,适用于动态调整和多步骤推理。 |
优化器(Optimizer):实现指标最大值的微调DSPy参数算法,由算法、指标(Metrics)、数据集(Dataset)、项目(Program)构成。
算法:用于迭代优化提示词参数的优化算法。
指标(Metrics):用于衡量算法优化效果的度量标准。
数据集(Dataset):优化提示词的数据集,与签名输入输出内容定义一致的、数据实例对象构成的数据列表。
项目(Program):优化实体,通常为模块(Module)实例。
原理:针对项目(Program),利用优化算法,调整选择示例和参数,构成新的提示词,借助LLM获得预测结果,再利用指标(Metrics)计算预测结果判断是否符合预期,确定算法优化方向,最终不断迭代获得示例和最终参数。
相关优化器:
| 优化器 | 用途 |
|---|---|
| dspy.LabeledFewShot | 定义预测器使用k个样本的数量 |
| dspy.BootstrapFewShot | 引导式启动,利用少量示例来优化Prompt和权重。 |
| dspy.BootstrapFewShotWithRandomSearch | 在BootstrapFewShot的基础上增加了随机搜索的特性,生成不同示例集,评估每个示例集性能,最后选择最佳Prompt和模型权重。 |
| dspy.Ensemble | 将多个程序集成,统一不同的输出为单一结果 |
| dspy.BootstrapFinetune | 将提词器设定为BootstrapFewShot,专门用于编译过程中的微调 |
使用注意事项:
- 在使用pip时,Windows安装DSPy前要先安装Microsoft C++ Build Tools,因为DSPy中的包madoka需要编译C/C++的扩展,否则会报这个错误
1 | error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/ |
在linux下则没有这个问题,可以直接使用 pip install -U dspy命令正常安装。
2. 在linux中注意检查pip和Python是否在同一个环境,命令which python和which pip如果是相同路径,则为同一个环境。
3. dspy.OpenAI/dspy.teleprompt.BootstrapFewShotWithOptuna从dspy 0.4开始已经移除,使用dspy.OpenAI需要使用dspy.configure()来设置配置模型,或者降级使用dspy版本。
4. dspy的官方文档设计并不友好,缺乏新手指引类的入门教程,学习和掌握难度比较大,建议先从样例开始学习。
5. 使用dspy.LM前需要注意调用大模型的API,例如export OPENAI_API_KEY等信息。
参考样例-数学推理
1 | # 使用时需要注意在Conda中安装更新dspy、datasets,conda install -c conda-forge dspy/datasets |
日后计划
研究PromptWizard框架,并和DSPY做对比,看看二者的优劣。
参考文献
[1] DSPy 从入门到劝退
[2] DSPY简易教程
[3] DSPy入门:再见提示,你好编程
[4] DSPy实战:三十分钟无痛上手自动化Prompt框架
[5] DSPy:开源大语言模型的革命
[6] LLMs之DSPy:DSPy(可优化RAG系统)的简介、安装和使用方法、案例应用之详细攻略
[7] 告别提示工程,未来属于DSPy(上)
[8] 告别提示工程,未来属于DSPy(下)
[9] Tutorial: Math Reasoning
[10] Towards Data Science
[11] Intro to DSPy: Goodbye Prompting, Hello Programming!
[12] LangGPT —— 人人都可编写高质量 Prompt

